42. Appendix 1 – DPDK Configuration¶
Wanguard 8.3 is compatible with DPDK 23.11 running on Ubuntu 18 to 22, Debian 10 to 12, and Rocky/AlmaLinux 8 or 9. The code is currently optimized for the Broadwell microarchitecture and it runs on every Intel microarchitecture starting with Sandy Bridge (Ivy Bridge, Haswell, Broadwell, Skylake, etc.) as well as on AMD Zen processors. For other limitations of DPDK, please consult the comparison table from the Choosing a Method of DDoS Mitigation chapter.
To use DPDK 23.11, follow the installation guide from https://www.dpdk.org and allocate at least 8 hugepages, each with 1 GB page size. When building DPDK, make sure that libpcap-dev is installed, to be able to capture packet dumps. It’s also recommended to follow the BIOS optimization steps provided by DPDK.
42.1. Application Workflow¶
The architecture of the application is similar to the one presented in the following diagram, which illustrates a specific case of two I/O RX and two I/O TX lcores (logical CPU cores) off-loading the packet Input/Output overhead incurred by four NIC ports, with each I/O lcore handling RX/TX for two NIC ports. The RX lcores are dispatching the packets toward two Distributor cores which are distributing them to six Worker lcores.
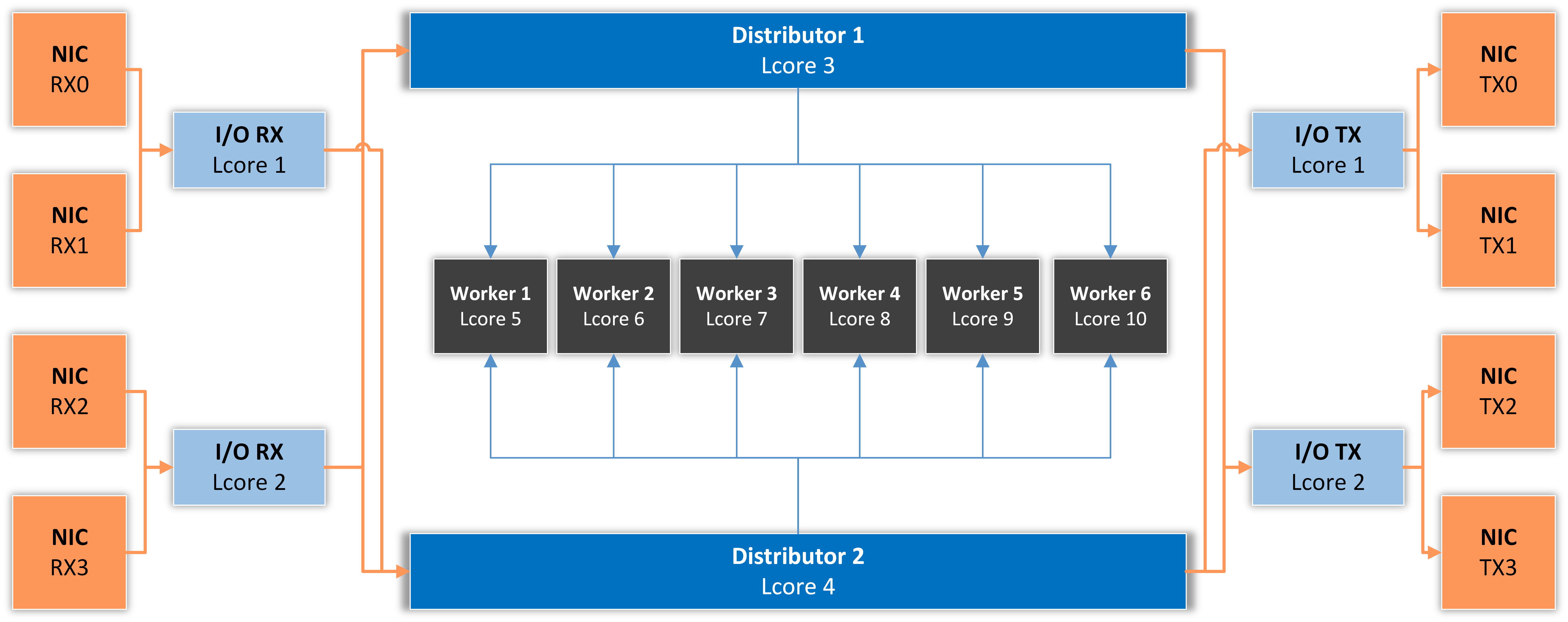
I/O RX Lcore performs packet RX from the assigned NIC RX rings and then dispatches the received packets to one or more distributor lcores using RSS or a round-robin algorithm.
Distributor Lcore reads packets from one or more I/O RX lcores, extracts packet metadata, performs the Dataplane firewall’s functionality, and dispatches packet metadata to one or more Worker lcores.
Worker Lcore performs heavy-weight and CPU-intensive tasks such as traffic analysis and attack detection.
I/O TX Lcore performs packet TX for a predefined set of NIC ports. The packets are forwarded in batches of minimum 4, so the latency will be very high (>50 ms!) if the application forwards just a few packets per second. On thousands of packets/s, the latency falls well under one millisecond.
The application needs to use one Master Lcore to aggregate data from the workers.
42.2. DPDK Capture Engine Options¶
42.3. DPDK Configuration Example¶
Execute the script usertools/cpu_layout.py from the your dpdk source directory to see the CPU layout of your server. The following configuration assumes this CPU layout of a 14-core Xeon processor: Core 0 [0, 14], Core 1 [1, 15], Core 2 [2, 16], Core 3 [3, 17], Core 4 [4, 18], Core 5 [5, 19], Core 6 [6, 20], Core 8 [7, 21], Core 9 [8, 22], Core 10 [9, 23], Core 11 [10, 24], Core 12 [11, 25], Core 13 [12, 26], Core 14 [13, 27].
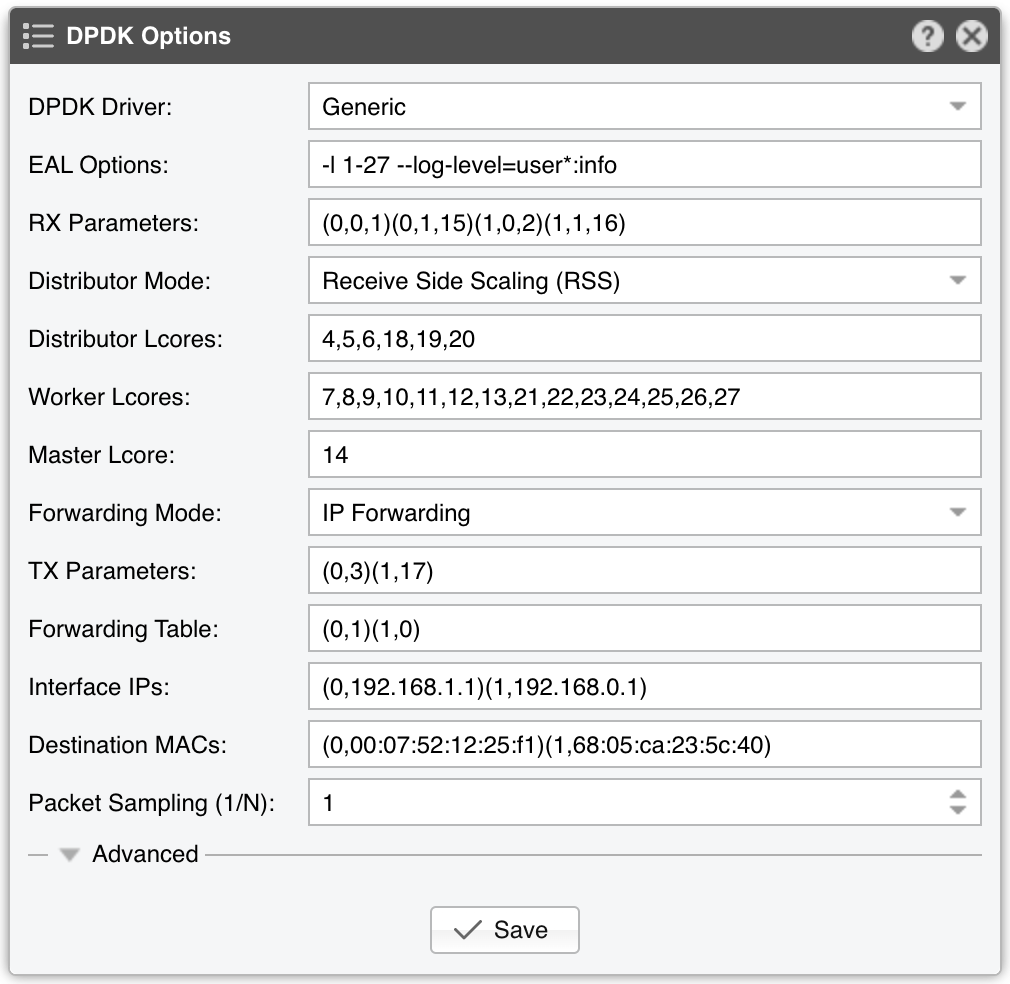
EAL Options contains the parameter “-l 1-27” which configures DPDK to use the lcores 1 to 27 (28 lcores = 14-core CPU with Hyper-threading enabled). The parameter “-n 4” configures DPDK to use 4 memory channels which is the maximum of what the reference Intel Xeon CPU (14-core Broadwell) supports. The parameter “–log-level=user*.info” activates the logging of the DPDK engine in syslog.
The RX parameters configure the application to listen to the first two DPDK-enabled interfaces (0 and 1), on two NIC queues (0 and 1), and to use two CPU cores for this task (15 and 16 are the hyper-threads of cores 1 and 2).
The Distributor Mode setting ensures that the packets will be forwarded in the same order.
Three CPU cores are used for the Dataplane firewall and to distribute packets to the workers: 4, 5 and 6 (18, 19 and 20 are hyper-threads).
Seven CPU cores are used for packet analysis and attack detection: 7 to 13 (21 to 27 are hyper-threads).
The Master lcore 14 is the hyper-thread of CPU core 0, which is the OS uses.
In this example, the DPDK Engine acts as a L3 pseudo-router in order to use an out-of-line topology via BGP, so the Forwarding Mode parameter is set to IP Forwarding.
The TX parameters configure the application to use a single CPU core for TX. Lcore 3 sends packets over port 0, while lcore 17 (hyper-thread of CPU core 3) sends packets over port 1.
The Forwarding Table value specifies that incoming packets on port 0 should be sent to port 1 and vice versa.
The Interface IPs parameter specifies that DPDK Engine should respond to ARP requests on port 0 with the IP 192.168.1.1, and to ARP requests on port 1 with the IP 192.168.0.1. So, when a router wants to forward packets to 192.168.1.1 or 192.168.0.1, the DPDK Engine responds with the MAC of interface 0 or 1. After the ARP is received by the router, it will then be able to start sending packets to the right interface.
Note
The distribution of lcores can be optimized by observing the performance-related statistics from Reports » Devices » Overview » Dataplane.