38. Appendix 1 – DPDK Configuration¶
Warning
The DPDK port is currently in a “Technological Preview” state. The support is very limited and the software is not deemed as stable enough to use it in production!
Wanguard 8.0 supports DPDK version 19.11.2 on Intel microarchitectures starting with Sandy Bridge (Ivy Bridge, Haswell, Broadwell, Skylake, etc.). The code is currently optimized for Broadwell. NICs that need special drivers for DPDK (e.g. Mellanox) might not be supported. For other limitations of DPDK please consult the table from the Choosing a Method of DDoS Mitigation chapter.
To use DPDK 19.11.2, follow the installation guide from http://www.dpdk.org and allocate at least 8 hugepages each with 1 GB page size. There are several BIOS optimization settings required, as well as a number of kernel parameters that increase the performance of the server. It may be possible to purchase preconfigured appliances, already optimized for DPDK, from https://www.andrisoft.com/hardware/anti-ddos-appliance.
38.1. Application Workflow¶
The architecture of the application is similar to the one presented in the following diagram which illustrates a specific case of two I/O RX and two I/O TX lcores (logical CPU cores) off-loading the packet Input/Output overhead incurred by four NIC ports, with each I/O lcore handling RX/TX for two NIC ports. The RX lcores are dispatching the packets toward two Distributor cores which are distributing them to six Worker lcores.
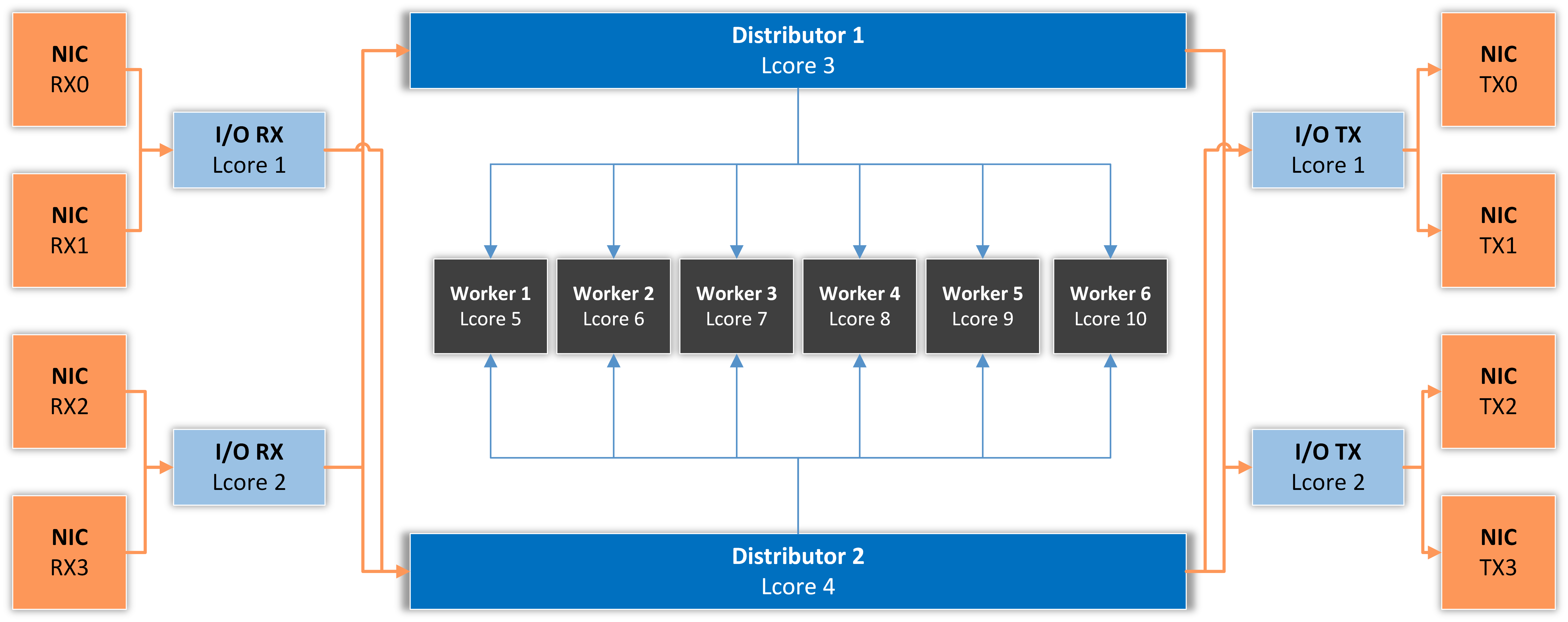
I/O RX Lcore performs packet RX from the assigned NIC RX rings and then dispatches the received packets to one or more distributor lcores using RSS or a round-robin algorithm.
Distributor Lcore reads packets from one or more I/O RX lcores, extracts packet metadata, performs the Dataplane firewall’s functionality, and dispatches packet metadata to one or more Worker lcores.
Worker Lcore performs the most heavy weight and CPU-intensive tasks such as traffic analysis and attack detection.
I/O TX Lcore performs packet TX for a predefined set of NIC ports. The packets are forwarded in batches of minimum 4, so the latency will be very high (>50 ms!) if the application forwards just a few packets per second. On thousands of packets/s the latency falls well under 1 millisecond.
The application needs to use one Master Lcore to aggregate data from the workers.
38.2. DPDK Capture Engine Options¶
38.3. DPDK Configuration Example¶
Execute the script usertools/cpu_layout.py from the your dpdk directory to see the CPU layout of your server. The following configuration assumes this CPU layout of a 14-core Xeon processor: Core 0 [0, 14], Core 1 [1, 15], Core 2 [2, 16], Core 3 [3, 17], Core 4 [4, 18], Core 5 [5, 19], Core 6 [6, 20], Core 8 [7, 21], Core 9 [8, 22], Core 10 [9, 23], Core 11 [10, 24], Core 12 [11, 25], Core 13 [12, 26], Core 14 [13, 27].
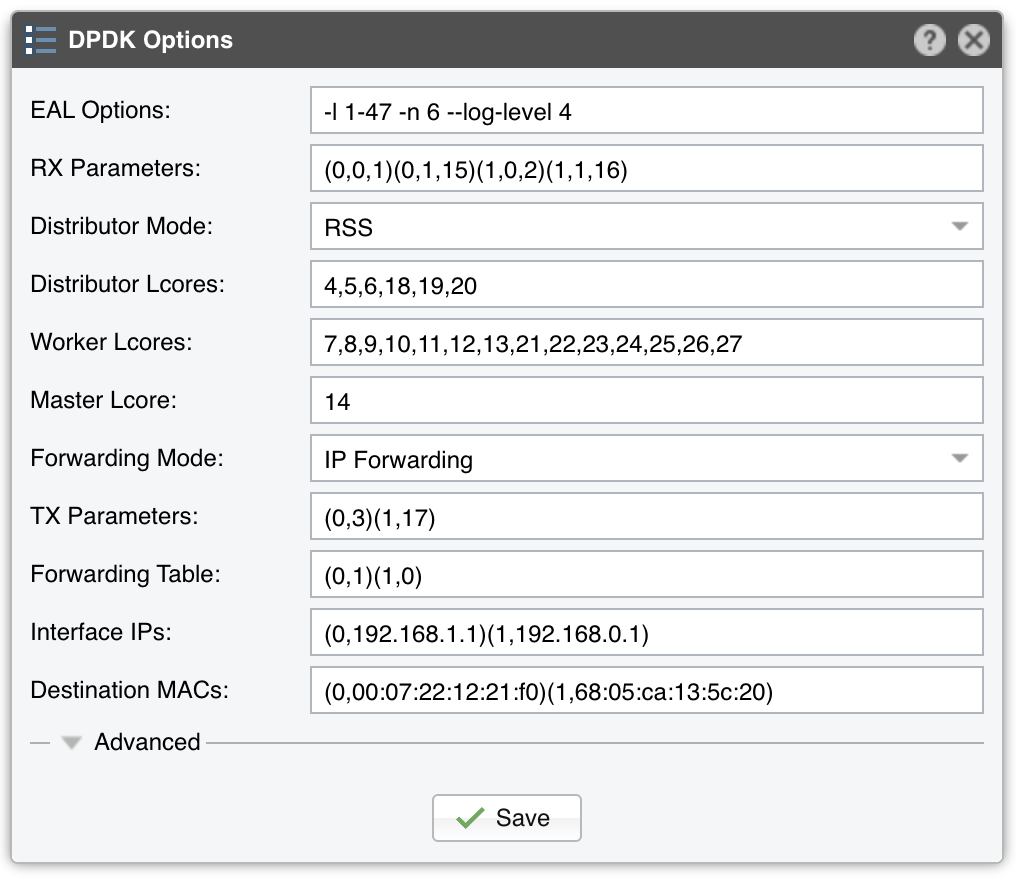
EAL Options contains the parameter “-l 1-27” which configures DPDK to use the lcores 1 to 27 (28 lcores = 14- core CPU with Hyper-threading enabled). The parameter “-n 4” configures DPDK to use 4 memory channels which is the maximum of what the reference Intel Xeon CPU (14-core Broadwell) supports.
The RX parameters configure the application to listen to the first two DPDK-enabled interfaces (0 and 1), on two NIC queues (0 and 1), and to use two CPU cores for this task (15 and 16 are the hyper-threads of cores 1 and 2).
The Distributor Mode setting ensures that the packets will be forwarded in the same order.
Three CPU cores are used for the Dataplane firewall and to distribute packets to the workers: 4, 5 and 6 (18, 19 and 20 are hyper-threads).
Seven CPU cores are used for packet analysis and attack detection: 7 to 13 (21 to 27 are hyper-threads).
The Master lcore is the hyper-thread of CPU core 0 which is used by the OS.
The TX parameters configure the application to use a single CPU core for TX. Lcore 3 sends packets over port 0, while the lcore 17 (hyper-thread of CPU core 3) sends packets over port 1.
The Forwarding Table value specifies that incoming packets on port 0 should be sent to port 1, and vice versa.